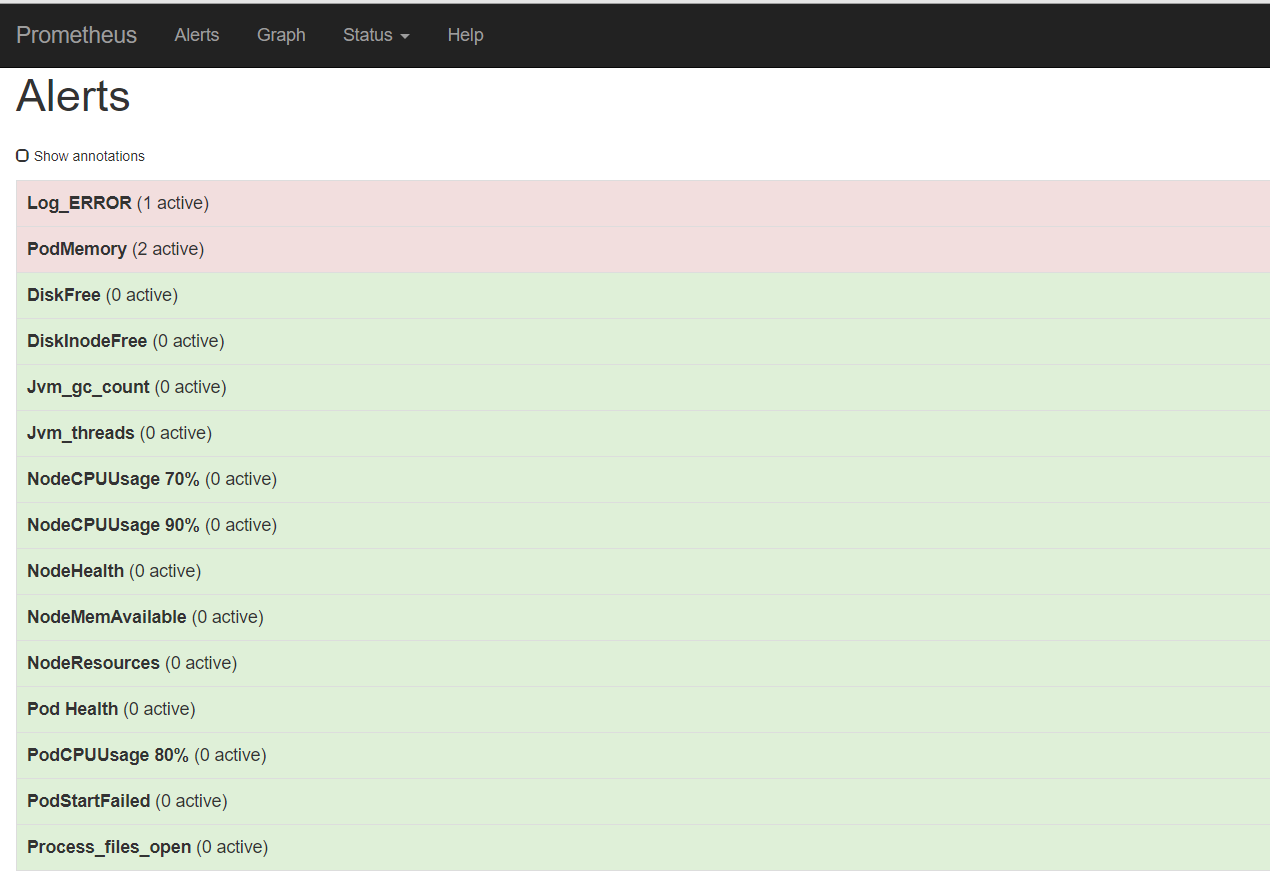
写告警规则,首先要把Prometheus的查询搞定
嗯,然后开始我的各种奇葩写法
groups:
- name: NodeUsage
rules:
- alert: NodeCPUUsage 70%
expr: floor((100 - (avg by (kubernetes_pod_name) (irate(node_cpu{kubernetes_pod_name=~"node-.*",mode="idle"}[5m])) * 100))) > 70
for: 1m
labels:
level: "9"
equal: "NodeCPUUsage"
annotations:
summary: "Node CPU 使用率"
description: "%"
- alert: NodeCPUUsage 90%
expr: floor((100 - (avg by (kubernetes_pod_name) (irate(node_cpu{kubernetes_pod_name=~"node-.*",mode="idle"}[5m])) * 100))) > 90
for: 1m
labels:
level: "10"
equal: "NodeCPUUsage"
annotations:
summary: "Node CPU 使用率"
description: "%"
- alert: NodeMemAvailable
expr: floor(((node_memory_MemAvailable / node_memory_MemTotal))*1000)/10 < 5
for: 1m
labels:
level: "10"
equal: "NodeMemAvailable"
annotations:
summary: "Node 内存 可用率"
description: "%"
- alert: DiskFree
expr: floor(node_filesystem_avail{device="rootfs"} /1000000000) < 15
for: 1m
labels:
level: "10"
equal: "DiskFree"
annotations:
summary: "硬盘 可用率"
description: "%"
- alert: DiskInodeFree
expr: floor(container_fs_inodes_total{kubernetes_io_hostname=~"cn-.*",device="/dev/vda1",id="/"} / container_fs_inodes_free{kubernetes_io_hostname=~"cn-.*",device="/dev/vda1",id="/"}) > 70
for: 1m
labels:
level: "10"
equal: "DiskInodeFree"
annotations:
summary: "硬盘 inode使用率"
description: "%"
- alert: NodeHealth
expr: up{nodename=~"cn-.*"} == 0
for: 1m
labels:
level: "10"
equal: "NodeHealth"
annotations:
summary: "节点健康情况"
description: ""
- alert: NodeResources
expr: kube_node_status_condition{condition=~"OutOfDisk|MemoryPressure|DiskPressure",status!="false"}==1
for: 1m
labels:
level: "10"
equal: "NodeResources"
annotations:
summary: "节点资源不足"
description: "{ $condition }"
groups:
- name: Pod
rules:
- alert: PodCPUUsage 80%
expr: (sum(rate(container_cpu_usage_seconds_total[2m])) by (pod_name))/(sum(container_spec_cpu_quota) by (pod_name)/10000000) > 80
for: 1m
labels:
level: "10"
equal: "PodCPUUsage "
annotations:
summary: "Pod CPU 使用率"
description: "%"
- alert: PodMemory
expr: floor((container_memory_usage_bytes{pod_name!='',image!=''} / container_spec_memory_limit_bytes{pod_name!='',image!=''} > 0.8 and container_memory_usage_bytes{pod_name!='',image!=''} / container_spec_memory_limit_bytes{pod_name!='',image!=''} < 2)*1000)/10
for: 1m
labels:
level: "10"
equal: "PodMemory"
annotations:
summary: "Pod 内存使用率"
description: "%"
- alert: PodStartFailed
expr: kube_pod_status_phase{phase=~"Failed|Unknown"}==1
for: 1m
labels:
level: "10"
equal: "PodStartFailed"
annotations:
summary: "Pod 启动失败"
description: ""
groups:
- name: JavaServer
rules:
- alert: Pod Health
expr: up{job="java-pods"} == 0
for: 1m
labels:
level: "10"
equal: "Pod Health"
annotations:
summary: "程序响应超时"
description: ""
- alert: Jvm_threads
expr: jvm_threads_peak > 1000
for: 1m
labels:
level: "10"
equal: "Jvm_threads"
annotations:
summary: "Jvm线程数"
description: ""
- alert: Process_files_open
expr: process_files_open> 1000
for: 1m
labels:
level: "10"
equal: "Process_files_open"
annotations:
summary: "文件描述符数量"
description: ""
- alert: Jvm_gc_count
expr: idelta(jvm_gc_pause_seconds_count{action="end of major GC"}[1m]) > 0
for: 0s
labels:
level: "10"
equal: "Jvm_gc_count"
send: "info"
annotations:
summary: "full Gc次数"
description: ""
- alert: Log_ERROR
expr: floor(irate(logback_events_total{level="error"} [2m])) >10
for: 1m
labels:
level: "10"
equal: "Log_ERROR"
annotations:
summary: "错误日志数"
description: "/s"
未完待续~附图一张